【画像・動画生成AI スタートガイド】第3回です。前回は生成AIの「種類」を俯瞰しました。今回は、いよいよその「中身」に踏み込みます。Stable Diffusionは、与えられたテキスト(プロンプト)から画像を生成しますが、その仕組みは「テキストを解析し、それが示す画像の特徴を有する「潜在空間」からノイズを除去して高解像度化する」というものです。「拡散モデル」「CLIP」「U-Net」「VAE」といった専門用語が飛び交う世界ですが、本節ではこれらを順を追って説明できるレベルまで理解していきましょう。
【画像・動画生成AI スタートガイド】第2回
生成AIにはどんな種類がある?それぞれどのような特徴がある?
https://www.aicu.jp/post/260405
Stable Diffusionの3つの構造
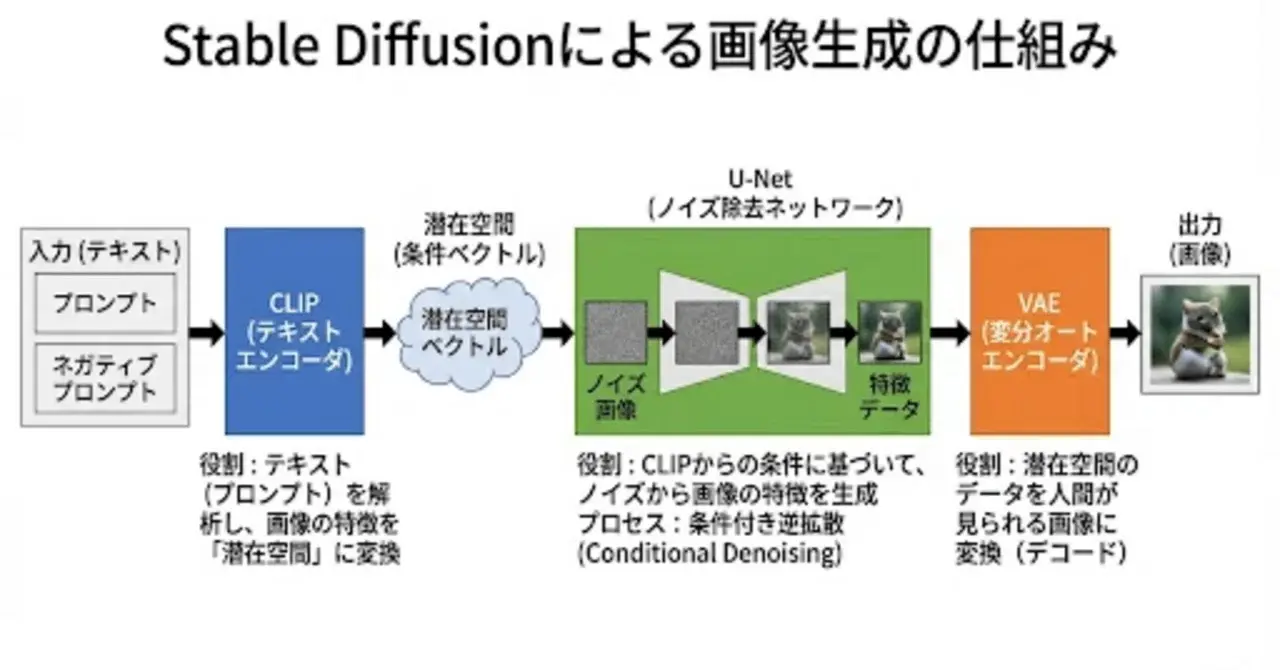
Stable Diffusionによる画像生成は、大きく3つのニューラルネットワーク構造で実現されています。

CLIP:テキスト(プロンプト)を解析し、画像の特徴を「潜在空間」に変換
U-Net:CLIPからの条件に基づいて、ノイズから画像の特徴を生成(条件付き逆拡散)
VAE:潜在空間のデータを人間が見られる画像に変換(デコード)
スタートは左上のテキスト(プロンプトとネガティブプロンプト)がCLIPから入力されます。CLIPの先は「U-Net」という大規模なニューラルネットワークに繋がっています。ここでCLIPから与えられた「プロンプト」と「画像の関係」の条件をもとにした「条件付き逆拡散」が行われます。最後に「VAE」を通して、潜在空間から画像への変換(デコード)が行われ、人間の目で見てわかる「生成画像」となります。
それぞれの構造について、詳しく見ていきましょう。
CLIP:言葉と画像をつなぐテキストエンコーダ
CLIPとは何か
「CLIP(Contrastive Language-Image Pre-training)」は、OpenAIが2021年2月に公開した、言語と画像のマルチモーダルモデルです。Stable Diffusionでは、プロンプト解析にテキストエンコーダーが使用されています。

CLIPが言語を解析できるのは、画像と言語を共通の低次元データである「潜在空間」に変換するタスクで訓練されたためです。インターネット上の膨大な「画像とその説明文のペア」を学習することで、テキストと画像間の意味や関係性を理解しています。
プロンプト解析の仕組み
プロンプト解析部分は、テキストをトークンに分解するテキストエンコーダー(ニューラルネットワーク)を使用します。トークンは単語単位や文字レベルなど様々ですが、機械学習と自然言語処理(NLP)において、トークンは1文字というよりは「走る」や、単語の一部であるサブワード(「走」「る」)といった語にあたると理解しておけば良いでしょう。
基本的な画像生成は、ユーザー入力のテキスト(プロンプト)から始まります。CLIPは、プロンプトから画像の特徴を解析し、「潜在空間」に変換します。この「潜在空間」を次のステップへ繰り返し与えることで、画像生成の方向性を制御します。
SDXLでの進化:2つのテキストエンコーダ
本書で中心的に扱う「SDXL」では、2つのテキストエンコーダが組み込まれています。
- OpenCLIP-ViT/G:オープンな実装、LAIONデータセットで学習
- CLIP-ViT/L:OpenAIが開発したCLIPモデルをベースに、Stable Diffusion用に 事前学習済み重みとして配布されているもの
これにより、より多様な「潜在空間」への埋め込みが可能になり、実質的に同時に2つのプロンプトを使用できるようになりました。
---
この記事の続きはこちら https://www.aicu.jp/post/260407
Originally published at note.com/aicu on Apr 7, 2026.
Comments