Stability AI社は、2022年8月に発表した言語で画像を自動生成するAI「Stable Diffusion」で世界中の注目を集めましたが、そればかりでなく、画像に関するいろいろな機能を持つ様々なモデルを提供しています。
そのうち、画像を日本語で解説したり、あるいは日本語の指示で選択することができる画像モデルも発表しています。最近リリースした2つの画像言語モデル、Japanese Stable VLMとJapanese Stable CLIPについて、その違いとユースケースを「実際に使って遊んでみる」ところまで紹介します。是非冬休みにご家族ご一緒に遊んでみてください。
これらのモデルは、日本語に特化したモデルです。
- Japanese Stable VLM:一つの画像から、それを適切に表現する日本語の説明が欲しいときに使う。
- Japanese Stable CLIP:数多くの画像から、日本語の指示で一つを選択するときに使う。
と大きな違いがあり、用途に応じて使い分けができます。以下、詳細な情報と想定される用途について解説します。
2つの画像言語モデルの比較
Japanese Stable VLM
- 日本語画像言語モデル(Vision-Language Model、略してVLM)の一種です。
- 特徴: 日本語で説明を生成する画像キャプショニング機能を有します。質問応答機能も備えています。
- パフォーマンス:日本語で学習しているため、日本語で正確に回答することが可能。
- ユースケース: 単一画像から日本語での詳細な説明を得たい場合に最適です。
Japanese Stable VLMの利用イメージ
Japanese Stable CLIP
- 日本語画像言語特徴抽出モデル(Contrastive Language–Image Pretraining、略してCLIP)の一種です。
- 特徴: 日本語テキストに基づいて、多くの画像の中から最も適切なものを見つけ出す機能を持っています。
- パフォーマンス:類似の日本語対応CLIPモデルの中で、最も高いスコア。
- ユースケース: 多数の画像から、特定の条件に合致するものを日本語で選択したい場合に適しています。
Japanese Stable CLIPの利用イメージ



2つのモデルの想定される用途
いずれも発表間もないことから、実際のユースケースはこれからとなりますが、上記の機能を活用し、VLM、CLIPについて、その能力を最大限に生かした用途を考えてみました。
VLM
①デジタルマーケティングと広告: 画像キャプショニング機能を利用して、製品やブランドのビジュアルコンテンツに対して適切な説明を自動生成することができます。これは、オンライン広告、ソーシャルメディアキャンペーン、eコマースサイトでの商品表示などに活用可能できるしょう。
②教育: 教材の作成や、学習者が提出した画像に対する自動フィードバック提供などに活用できます。また、視覚的な教材に対する簡潔で正確な説明を生成することで、教育効果を高めることが可能となるでしょう。
③コンテンツモデレーション: ソーシャルメディアプラットフォームやフォーラムなどで、投稿される画像の内容を分析し、不適切または規約違反のコンテンツを自動で識別するために使用できます。これにより、安全なオンライン環境の維持に貢献することが可能でしょう。
④映像・動画分析: 映像や動画のフレームを抽出し、その内容についてのキャプションを生成することで、映像コンテンツの要約や解析に役立てることができます。これはニュースメディア、映画制作、スポーツ分析などで有用でしょう。
⑤障害者サポート: 視覚障害者をサポートするために、ウェブサイトやアプリケーション内の画像に対して詳細な説明を提供することができます。これにより、より包括的なデジタルアクセスを提供し、情報の平等なアクセスを促進することができるでしょう。
CLIP
①画像ベースの検索エンジン: 日本語テキストにより、最適な画像を高精度で検索することができます。これは、オンラインショッピング、デジタルアーカイブ、または教育資料の検索などに有用ではないでしょうか。
②画像分類: 未知の画像に対して、事前学習なしに分類を行うことができます。この機能を用いると、急速に変化するトレンドやニュースの画像分析、あるいは新しい種類の製品の自動認識に役立たせることができる可能性があります。
③コンテンツ生成と編集: 「Japanese Stable CLIP」を他のモデルと組み合わせることで、日本語のテキストから画像を生成するtext-to-imageタスクや、画像からテキストを生成するimage-to-textタスクに拡張することが可能です。これは、クリエイティブなコンテンツ制作や自動ニュース記事生成などに活用できるのではないかと思われます。
④画像とテキストを組み合わせた学習と分析: 画像とテキストの両方を組み合わせたデータを分析し、より多くの情報を抽出することができます。これは、市場調査、メディア分析、教育研究などに有用ではないかと思われます。
⑤障害者支援: 視覚障害者のための支援ツールとして使用できます。例えば、画像に含まれる情報を日本語のテキストで説明し、よりアクセスしやすいコンテンツを提供することができます。
参考:2つの画像言語モデルの詳細情報
|
Japanese Stable VLM |
Japanese Stable CLIP |
|
|
モデルの分類 |
日本語画像言語モデル |
日本語画像言語特徴抽出モデル |
|
ベースとなる |
LLaVA-1.5 |
SigLIP |
|
日本語モデル |
JSLM Instruct Gamma 7B(Stabiily AI社が開発した日本語専用大規模言語モデル) |
‐ |
|
商用 |
商用利用可 |
商用利用可 |
|
機能 |
1.入力した画像に対し、文字で説明を生成できる画像キャプショニング機能 |
1.ゼロショット画像分類※(事前に特別な学習を行わず画像を分類する方法)が可能 |
|
利用ケース |
一つの画像から、それを適切に表現する日本語の説明が欲しい時 |
数多くの画像から、日本語の指示で一つを選択したい時 |
|
特徴 |
日本語で学習しているため、日本語で回答することが可能 |
類似の日本語対応CLIPモデルの中で、最も高いパフォーマンス |
せっかくなので実際に使って遊んでみましょう!
さて、「つくる人をつくる・わかるAIを届ける」をビジョンに活動している AICU(アイキュー)ですが、
先日、取材でStability AI の Jerryさんと マーケティング担当の Satioさんと雑談していたときのことです……。
しらいはかせ(以下、白):先日の講演でも、Stability AI 社が開発した日本語VLM(Vision-Language Model)と日本語CLIPについての話題がありました。
Jerry Chi:ありがとうございます
白:CLIPは画像生成AI「Stable Diffusion」の内部でも使われていますね。でもたしかに、その重要性は『わかっているひとはわかっている』という感じですね…
Saito:うーん、そうですねえ…お客さんとお話していても、いまいち伝わりづらいですね。
Jerry Chi:日本語VLMは本当はすごいんですが、なかなか伝わってないかもですね
Saito:しらいはかせせっかくだからAICUで作ってみてくださいませんか?
白:えっ……?(喜)
ということで、どういうわけか AICU社内で「日本語VLMとCLIPを使いこなすAI活用アイディア」、特にビジネスアイディア募集!ということでAICU社 AIDXラボとUSオフィスのFounderの Koji Tokudaにも手伝ってもらって「オジサンでもできる!AI活用ビジネス社内ハッカソン」を開催してみたところ…
なんと全部で10個のアイディアと実験が出てきました。
いちおうお手元でも動きます!ので試してみてください
AICU社で人気!VIP向けAIワークショップはこちらから(初回無料)
特徴をまとめると、
「JSCLIPは速い、JSVLMは未知の対象に強い」
という点です。
詳細な用途とアイディア、実験を前後編に分けて紹介していきます。
なおソースコードと「めちゃくちゃ丁寧な初心者向け解説」は一番最後においておきます(リツートしていただけると無料で見れます)
Japanese Stable VLM [JSVLM]=説明が得意
-
日本語画像言語モデル(Vision-Language Model、略してVLM)の一種
-
特徴: 日本語で説明を生成する画像キャプショニング機能を有します。質問応答機能も備えています。
-
パフォーマンス: 日本語で学習しているため、日本語で正確に回答することが可能です。
-
ユースケース: 単一画像から日本語での詳細な説明を得たい場合に最適です。
-
サンプル: 公式 Google Colab 画像の説明を日本語で得ることができます
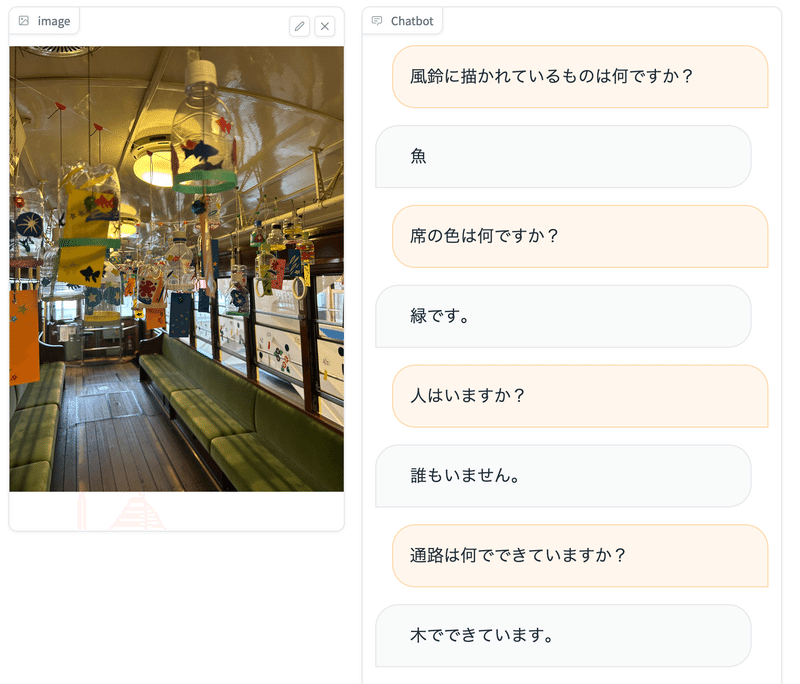
「風鈴」といった日本独特の知識を得ていることがわかります。
Japanese Stable CLIP [JSCLIP]=判定が得意
-
日本語画像言語特徴抽出モデル(Contrastive Language–Image Pretraining、略してCLIP)の一種です。
-
特徴: 日本語テキストに基づいて、多くの画像の中から最も適切なものを見つけ出す機能を持っています。
-
パフォーマンス: 類似の日本語対応CLIPモデルの中で、最も高いスコア
-
ユースケース: 多数の画像から、特定の条件に合致するものを日本語で選択したい場合に適しています。
-
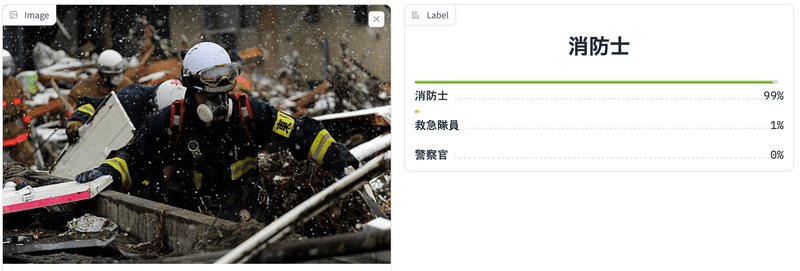
サンプル: 公式 Google Colab 入力画像から職業を判断するテキスト分類
JSVLMビジネスアイデア5連発
JSVLMとJSCLIPについて、どんな使い道がありそうでしょうか?
公式デモを触りながらアイディア出しをしてみました。
①デジタルマーケティングと広告分野
JSVLMの日本語分析力「画像キャプショニング機能」を利用して、製品やブランドの 未知のビジュアルコンテンツ に対して適切な説明を自動生成することができます。これはオンライン広告、ソーシャルメディアキャンペーン、eコマースサイトでの商品表示などに活用可能できるはずで、過去に画像分析を使ったインスタグラムでのファッション分析などでは活用事例があります。
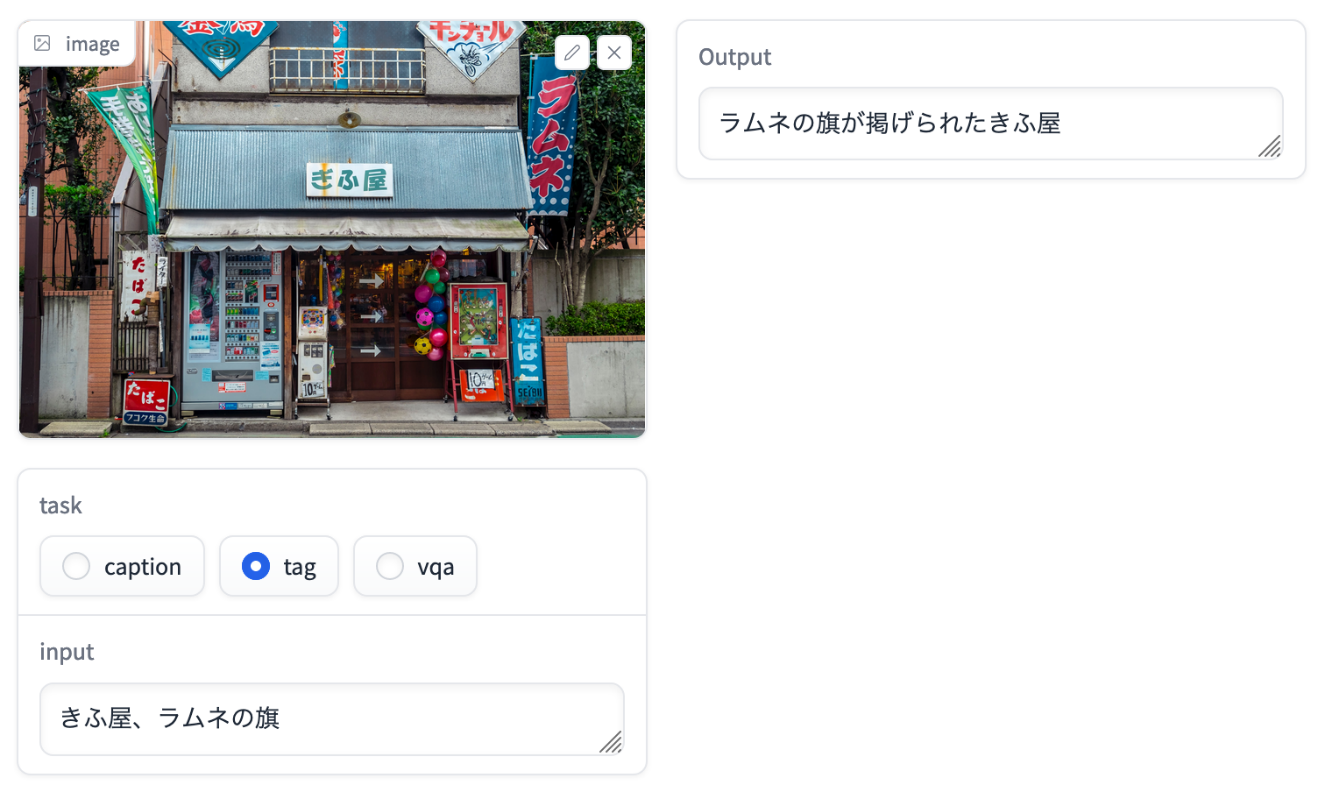
ちょっと実験してみましょう。Stability AI社のJSVLMのサンプルコードにはこのようなタスクが記載されています。

"caption": "画像を詳細に述べてください。",
"tag": "与えられた単語を使って、画像を詳細に述べてください。",
"vqa": "与えられた画像を下に、質問に答えてください。",
例えばここにWikipediaからお借りしてきた、ソフトボールの画像があります。まずはこの画像に「caption」で何が写っているかを分析してもらいますと、「黒いユニフォームを着た男性がバットを振っている」と回答されました。
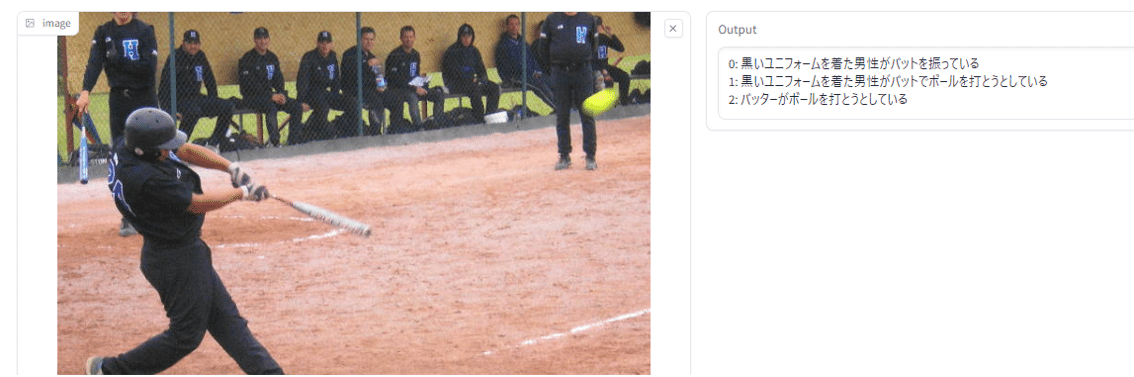
次に「tag」で入力に「ソフトボール,打者,ユニフォーム,バット,ボール,ヘルメット」といったソフトボールに関する用語を input に設定して処理をするとoutputには「0: ユニフォームとヘルメットをかぶった打者がバットでボールを打とうとしているソフトボール」とinputした用語を使って表現されました。

このようなプロンプトであれば比較的エンドユーザの方々でもチューニングできるかもしれませんね。
②教育
JSVLMは教材の作成や、学習者が提出した画像に対する自動フィードバック提供などに活用できそうです。視覚的な教材に対する簡潔で正確な説明を生成することで、教育効果を高めることが可能となるでしょう。例えば「TOEIC Listening & Reading Test」に出てくるような画像を「英語学習」ではなく、日本語で解説するような初等教育向けの事例をイメージしてみましょう。子どもたちのコグニティブトレーニングに役立つゲームシステムが作れそうです!このようなパズル的な認知力トレーニングは「コグトレ」として人気です。
たとえば以下の映像を試してみますと、「0:工場で働いている人々のグループ」や「1:労働者のグループが工場で働いています」と表現されました。

「1:労働者のグループが工場で働いています」
「2: 工場労働者のグループ」
ここには製造機械などが写っておらず、始業前のミーティング中の写真のようです。床のコンクリートやマーカー、流し台のような金属製の製品がならんでおり、場所が工場であると判断されました。さらに、人々は同じ色とスタイルの服装を着ていて、しかも少し黒っぽく汚れている服を着ている人もいることから制服であること「工場で働く労働者」である推論されています。しかも雑踏や家族連れではなく「グループ」であることが指摘されています。こういったコグニティブ、つまり認知の能力が必要な画像理解は、例えば教育のケースでは大変役に立ちます。
具体的に価値ある活用例としては英語や国語、社会の授業での活用。「この写真を見て作文してみて」と言っても多くの子どもたちは困ってしまうでしょう(きっと作文が嫌いになりますね!)。でも日本語VLMと対話的に注意深く認知的に見ていくことで「さっきまで何も見えていなかったけど……そうか、このひとたちは流し台を作る工場にいるんだ」「左下のひとは制服が違うね」といったディスカッションができるようになります。このような「視界に入っているが見えていない状態」、つまり「認識を超えた認知トレーニング」のきっかけになるようなVLMの使い方は、TOEICのような英語検定に対して問題の柔軟な難度設定や、家庭学習などでの評価やトレーニングに多大なるコスト効果を生みます。具体的には、都立高校の入試に導入されるスピーキングテストなどの練習例です。
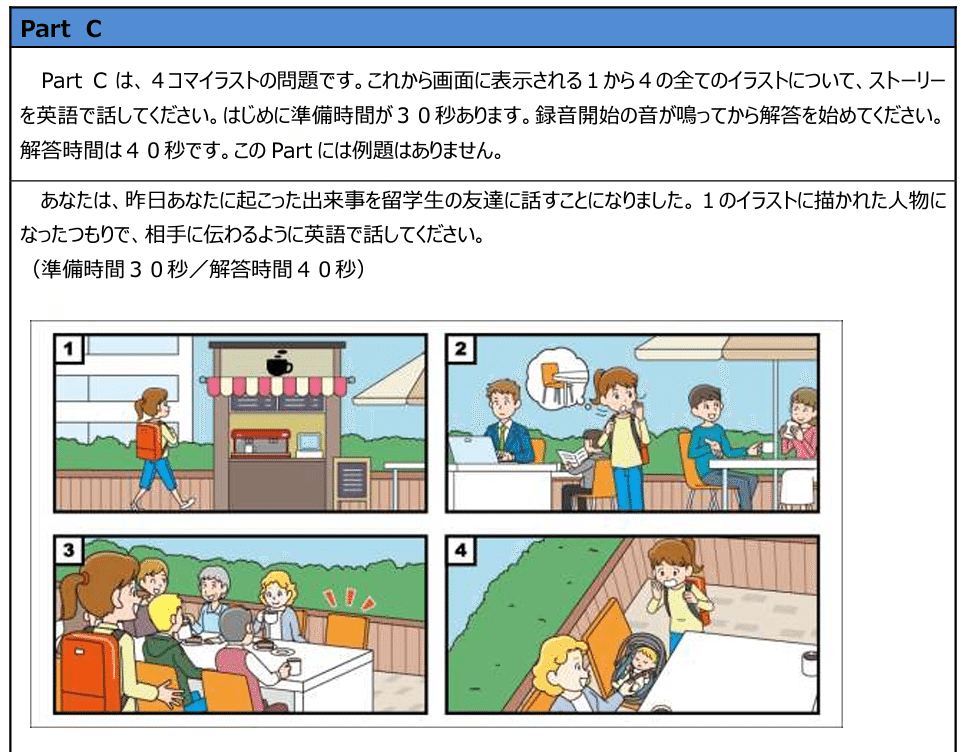
息子さんや娘さんにこんな実験して見てください。ヒーローになれますよ!
(え…コーヒーショップなんだこれ…気が付かなかった)
③コンテンツモデレーション
ソーシャルメディアプラットフォームやフォーラムなどで、投稿される画像の内容を分析し、不適切または規約違反のコンテンツを自動で識別するために使用できます。これにより、安全なオンライン環境の維持に貢献することが可能でしょう。例えば、学校の課外活動や学園祭などで、生徒さんが制作したYouTube動画を短い期間ですべてチェックするのは大変ですね!指定されたYouTubeチャンネルの動画を自動で分析して、JSVLMを使った日本語でのチェックを実施しておけば、生徒さんのクリエイティビティを阻害せずにスマートなコンテンツモデレーションが実施できそうです。

例えば、上のような画像を与えてみますと、「ショッピングモールを歩く人々」だと回答されました。人々が歩いている映像であることはすぐにわかりますが、ショッピングモールであると判断するには、少し難しい画像です。ところが、手提げ袋を下げている人がいること、遠くにレストランらしき画像が写っていること、床面は2種類の景観舗装材が使われていること、などから、ここがショッピングモールの中であると判定されました。実際に、これはショッピングモール内の画像ですが、顔を隠すために顔から上部は削除された画像です。VLMを使うことで、どんな場所で撮影したものかどうかを判定することが可能となり、コンテンツモデレーションにも役立てる事が可能となります。
YouTubeのコンテンツで実験してみた
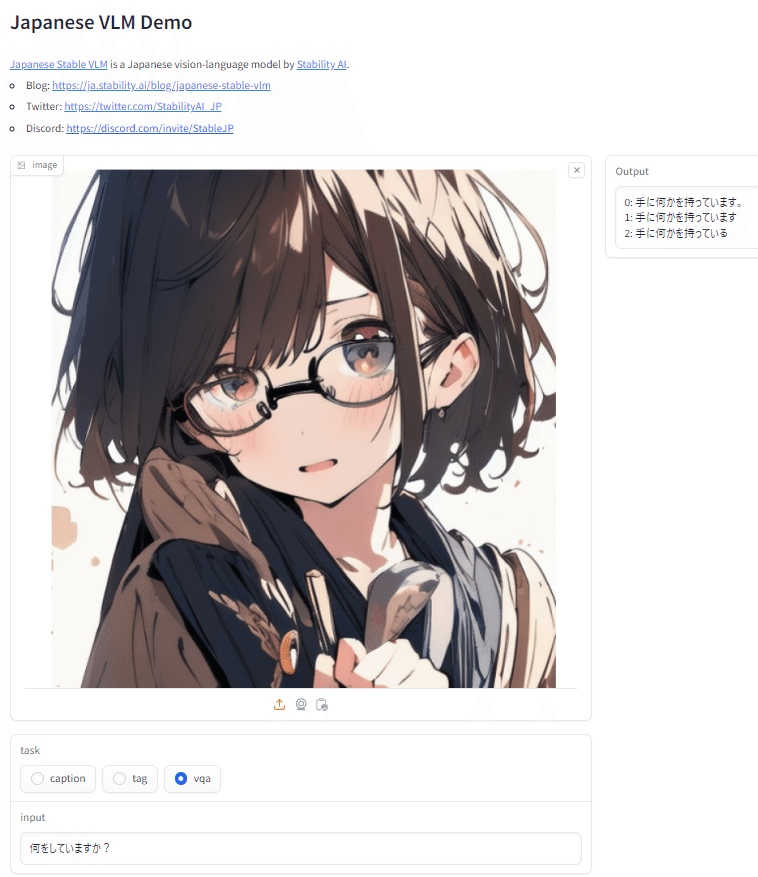
日本語VLMに「何をしていますか?裸ですか?」といった問いをすることで、未知のコンテンツの健全性を確認できますが、チェックする側としては複数の条件を何度も聞きたくはないので、同時に複数の質問に答えられるかも実験してみました。
事前学習ゼロ、未知のコンテンツに「ここはどこ?誰が居ますか?アジア人?裸ですか?」といった質問を同時にしてみます。
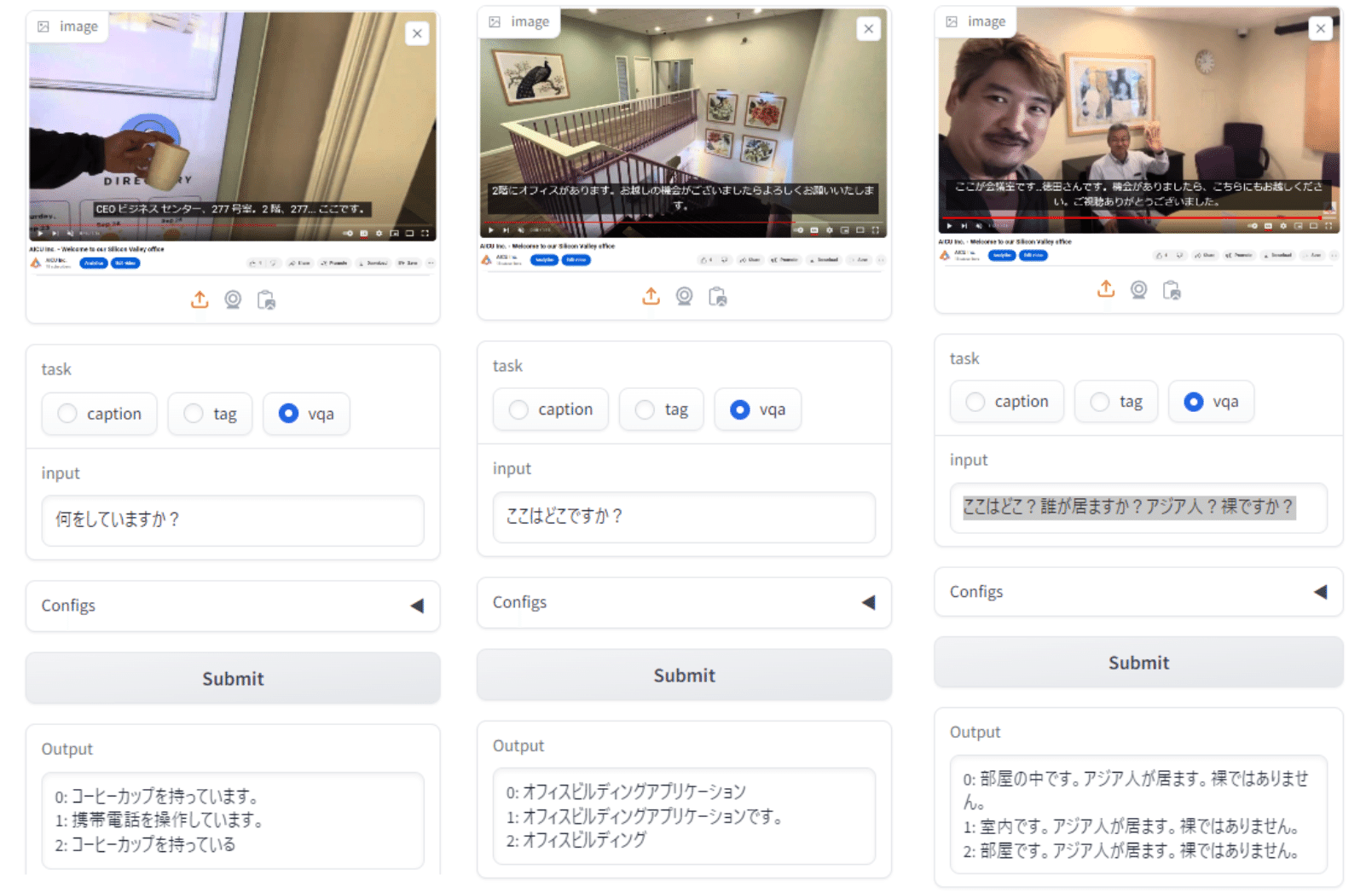
左: vqa「何をしていますか?」→コーヒーカップを持っています、携帯電話を操作しています。
中: vqa「ここはどこですか?」→オフィスビルディングアプリケーション
右: vqa「ここはどこ?誰が居ますか?アジア人?裸ですか?」→部屋の中です。アジア人が居ます。裸ではありません。
という感じに見事に未知の複雑なシーンを同時要素で判定できています。
④映像・動画分析
上記のコンテンツモデレーションの応用ですが、JSVLMを使って映像や動画のフレームを抽出し、その内容についてのキャプションを生成することで、映像コンテンツの要約や解析に役立てることができます。これはニュースメディア、映画制作、スポーツ分析などで有用でしょう。例えば「日本酒のCM」で、過去に製作したコマーシャルフィルム(CF)を分析して、「どれぐらいの秒数、日本酒の画像が含まれるCFが好まれたのか?」といったポストリサーチをすることもできそうです。
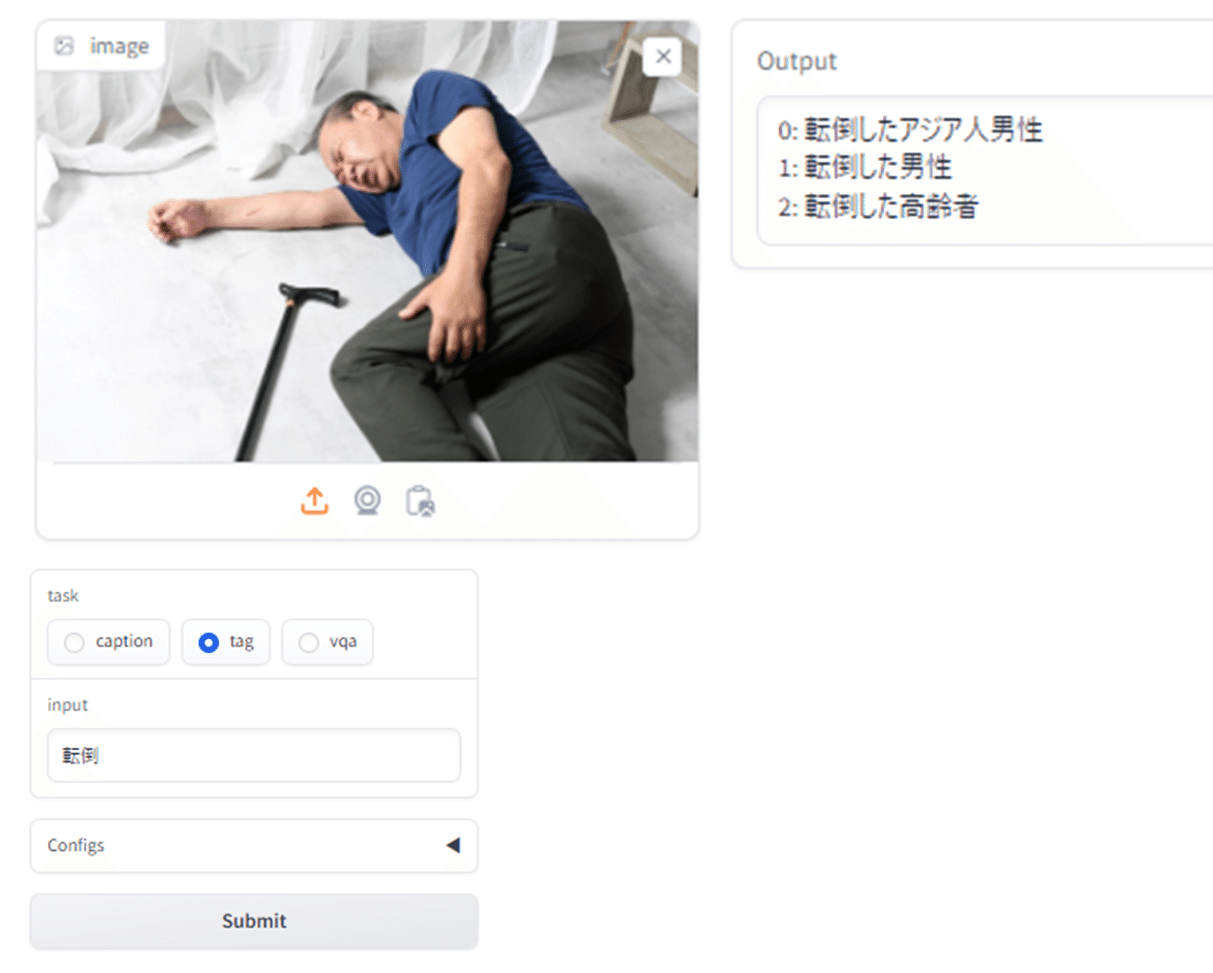
セキュリティカメラを想定して、こんな写真を試してみました。「転倒した高齢者」などと記していることから、VLMを使った高齢者のモニタリングが可能だと考えられます。高齢者の住む家に、監視カメラを設置することは既に行われていますが、他人から室内を直接覗かれることになり、プライバシーなどの問題が生じます。そのため、監視カメラの設置がなかなか進んでいない現状があります。このシステム全体をローカル内に設置し、実際の映像は室外には出さないようにします。転倒するなど異常事態が発生した際に自動的にアラートを出すだけにする事ができます。これにより、プライバシーが守られることになり、監視カメラの設置を拒む一人住まいの高齢者の家に、設置が促進される可能性が高まることが期待されます。
⑤アレルギーやカロリー計算、メニューやレシピ分析
例えば小規模な社員食堂で管理栄養士さんを配置することが難しい場合や、スマホアプリと連動して、アレルギーや生活習慣病対策をお助けするような用途、そして地域や季節・市場に合わせたメニューやレシピ分析はいかがでしょうか。先程のラーメンの応用ですが、アレルギー対象の品目やカロリー計算を簡易に行うことができるかもしれません。現在のJSVLMだけでは難しいかもしれませんが、原材料やカロリー計算のデータセット、重さと撮影条件を推定する技術と組み合わせて学習することで、より日本の食卓にあわせたサービス開発も可能かもしれません。
以下の例では、日本独自の料理であるお好み焼き(関西風)の写真を試してみました。
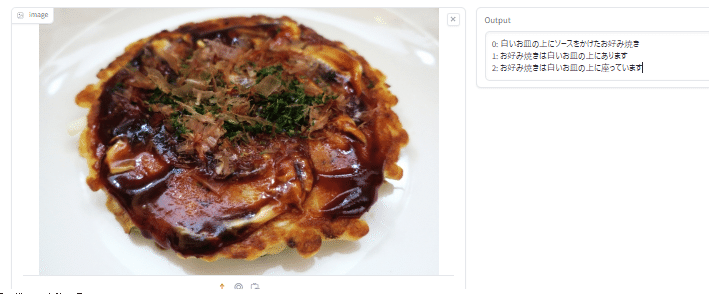
「白いお皿の上にソースをかけたお好み焼き」と見事に回答してくれました。このVLMモデルは、きちんと日本の画像を学習していることがわかりました。
さらにもう一つ。お好み焼きには関西風と広島風の2大流派があります。ネットでは時折、どちらが本家本元のお好み焼きか?と論争が起こるほど、お互いの地域では大きなこだわりがあるようです。
(私は広島出身なので見分けられますが)日本人であっても、それ以外の地域の方の中には、違いをよく知らない、という方もいらっしゃるでしょう。さて、VLMはきちんと区別してくれるでしょうか?それでは、VLMに「関西風ですか?」と質問してみることにしました。
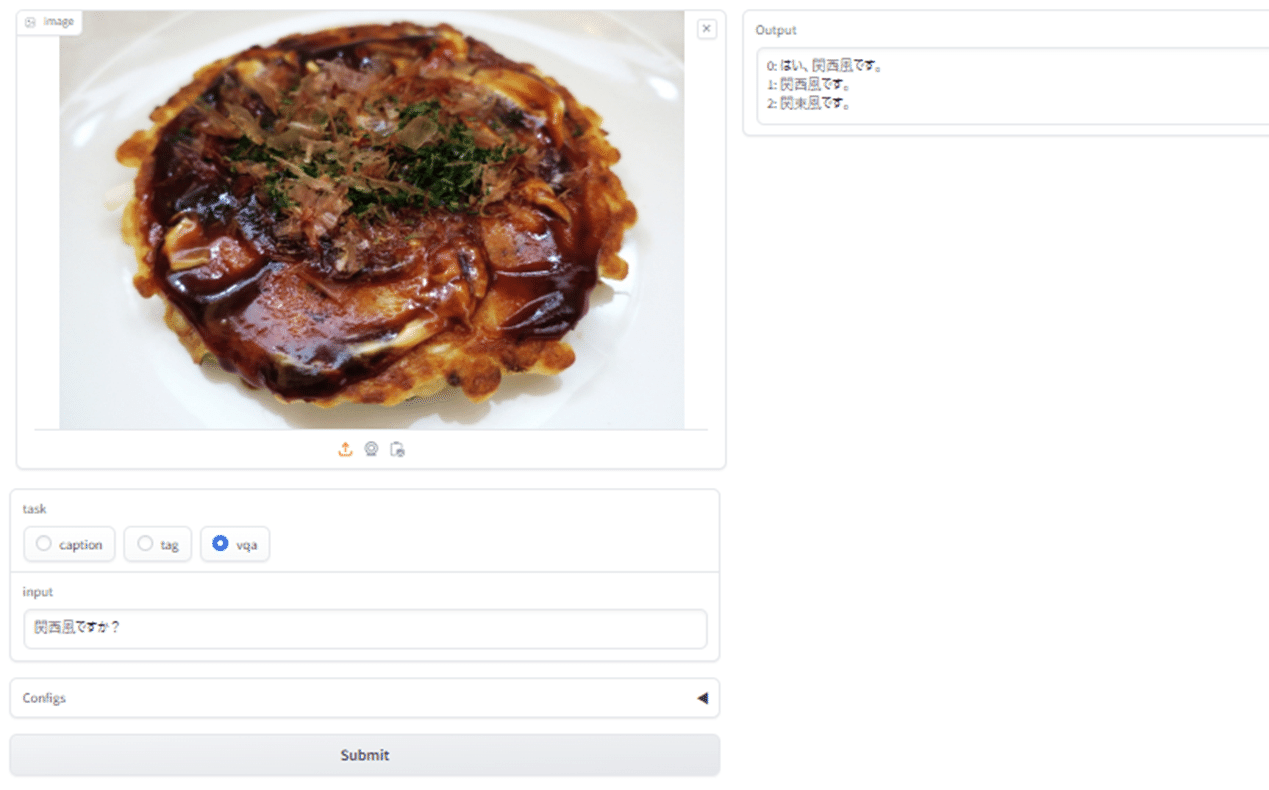
1:「関西風です」
2:「関東風です」
「はい、関西風です」と回答してくれました。正解です。「2:関東風です。」という答えもありましたが、ソースをかけた状態の関東風は関西風と極めて近く、見た目では区別がつかないことから、ある意味正解と言って良いでしょう。このように、
つまり日本語VLMは何に使えるのか?
→監視カメラの向こうの警備員とか!
このように、VLMは「対話的に未知の要素を解説」してくれます。
つまり画像の中身に対する事前の知識が必要ないのです。しかも日本語独自の知識がかなりあるようです。
オジサン的には「さてナンに使うかだよなア……」と言ってしまいそうですが、ここまで実験すればもうおわかりですね!
一番わかり易いユースケースとしては「監視カメラ+日本語VLM」ではないでしょうか。
・録画した画像を分析するのに実時間 × カメラの台数分必要
・広い農場が荒らされるので監視したい、しかし野生動物なのか何なのか、相手がわからないのでどんなトラップを仕掛けたらいいのか謎
・ショッピングモールの駐車場、深夜に誰かが何かをしているのだけど…
・監視カメラの向こう側にひとが居てくれたらどんなに助かるか
こんなJSVLM活用案件お待ちしております!
是非弊社も研究開発やPoC開発、実験や評価に伴走させていただきたいです
ちょっと小耳に入れておきたいいい話ですが、
「生成AIを導入するなら、最初にCFOと話をしよう」だそうですよ!
ちなみに Koji Tokuda はAICU社のCFOです。
元銀行系のオジサンでもできる!あなたならもっと上手にできるはず!
後編は、よりJSCLIPむきの実験・応用アイディアを紹介していきます!
ソースコードと使い方こちら!
前編の最後、こちらに今回使った Google Colab で動くサンプルコードを置いておきます。
https://github.com/aicuai/GenAI-Steam/blob/main/20231218_japanese_stable_vlm.ipynb
初心者向けの丁寧な解説もつけておきます!!
(1) 事前準備として、HuggingFaceのアカウントとJSVLMへのライセンスを取得するのを忘れずに、といっても、どちらも無料で設定できます。
(2) GitHubに置かれた実験用のソースコード(ipython notebook)にアクセス
https://github.com/aicuai/GenAI-Steam/blob/main/20231218_japanese_stable_vlm.ipynb
[Open in Colab]のボタンを押す前に、お使いのGoogleアカウントが個人もしくは所属企業のアカウントになっていることを確認します。
(意図しない場所に保存されることを防ぐため)
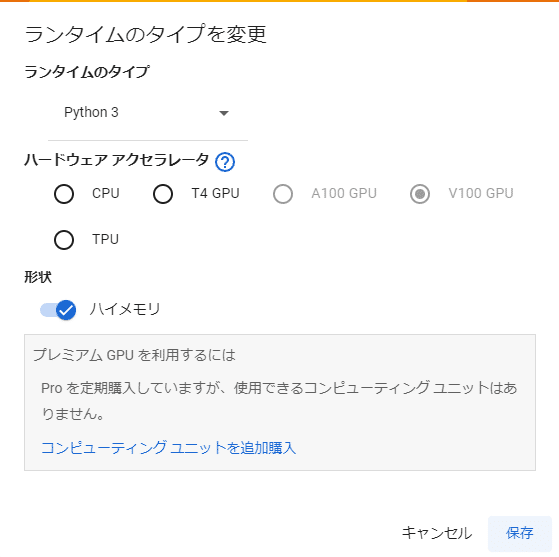
このスクリーンショットの場合は Google Colab Proに契約しています。1ヶ月1,179円でかなりパワフルな演算環境が手に入りますが、今回のサンプルは「T4 GPU」というプロ用GPUでも動作します。
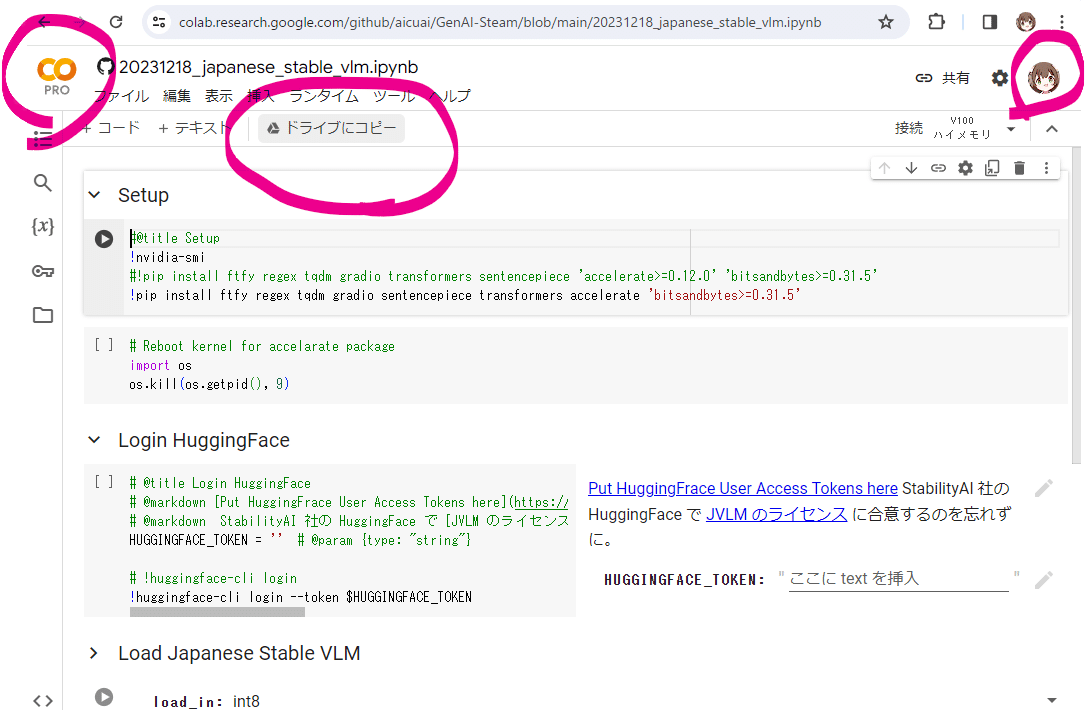
(3) この先、自分の Google Driveにこのスクリプトを保存して進行したいのでファイル名を変えて保存します。

(4) 左上「Setup」の下にある再生ボタン▶を押しましょう
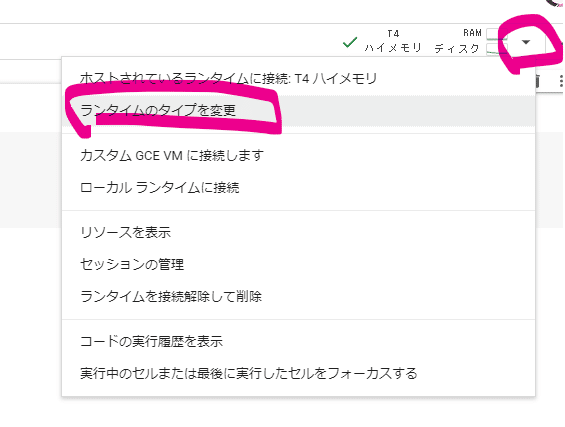
(5) ランタイムのタイプをGPUに変更します
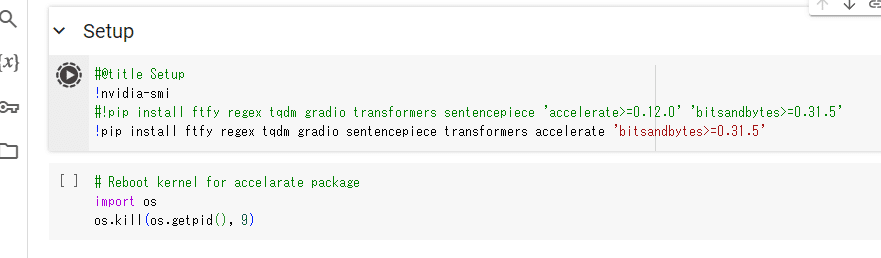
(6) 2番めのコードブロックを再度実行
これにより GPUを活用する accelerate というパッケージを入れて再起動することになります。
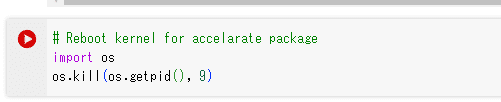
(7) 再度最初のセルを実行
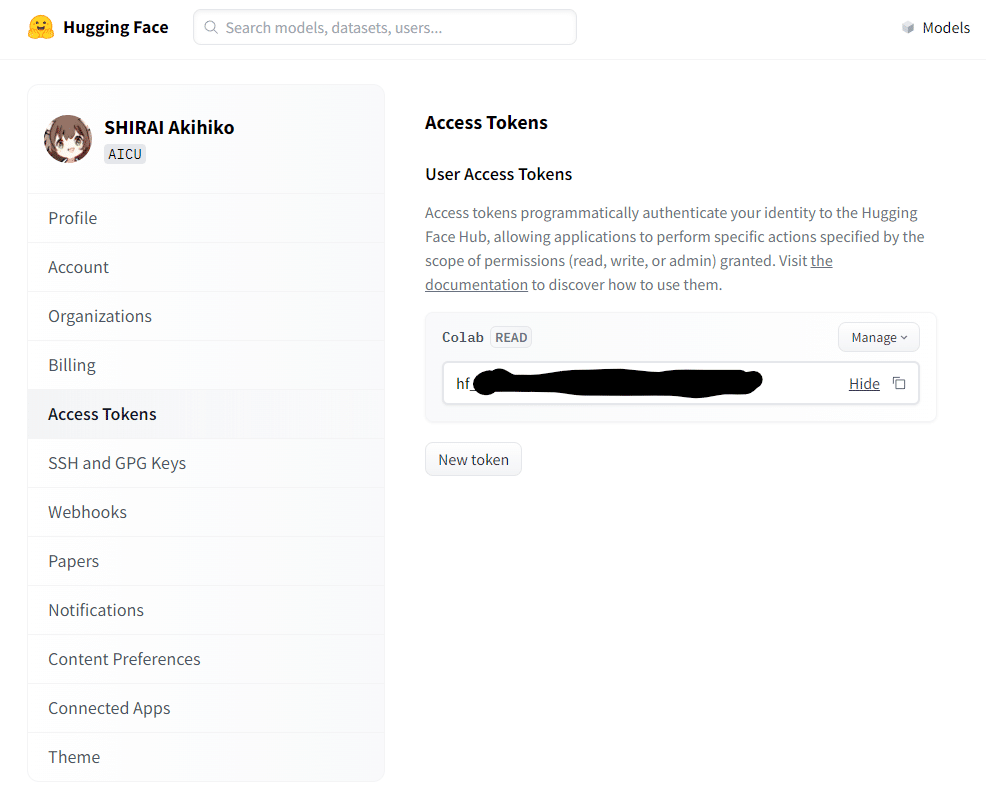
(8) Hugging Face の アクセストークンを入手
https://huggingface.co/settings/tokens
こちらのURLで取得できます。アクセストークンとは、HuggingFaceのアカウントに紐づいたカギで、ファイルのダウンロードやライセンスの確認に使われる「hf_」で始まる文字列です。流出させてしまった場合は慌てず「New token」で再生成しましょう。「Hide」の右の □ でクリップボードにコピーできます。
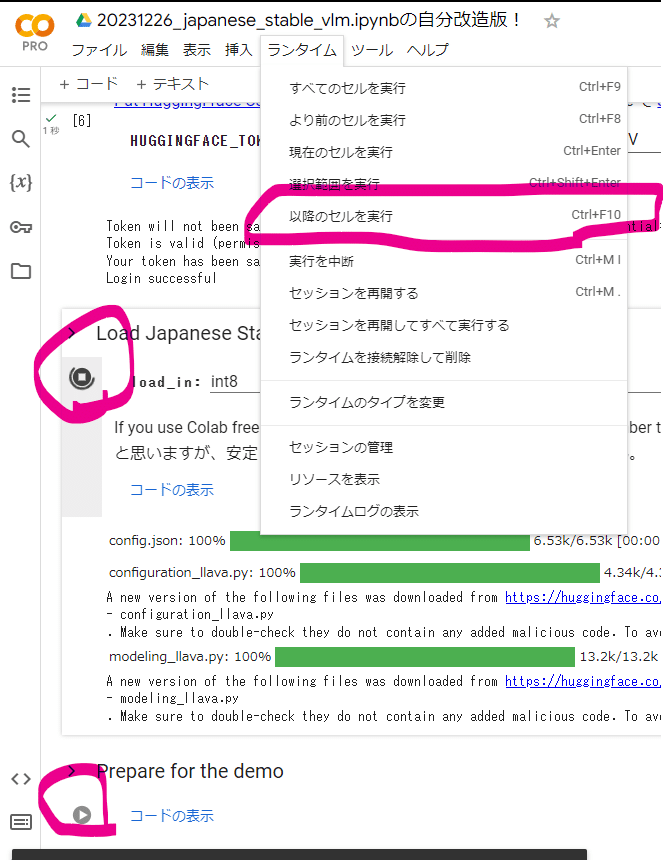
(9) Colab に戻り HUGGINGFACE_TOKEN に貼り付けて実行[▶]

(10) 以降のセルを実行、もしくは Ctrl + F10 で「以降のセルを実行」します
ここからさきはモデルのダウンロードがあって HuggingFace から5GBほどのファイルを(model.fp16-00001-of-0000{1-4}.safetensors)4つほどダウンロードするので10分ほどタバコ休憩などに行ってきて構いません。
このあいだに認識させたい画像を用意しておいてください。Webカメラも使えます。
(11) Gradio WebUIの起動!
さあここまでくれば起動するだけです!
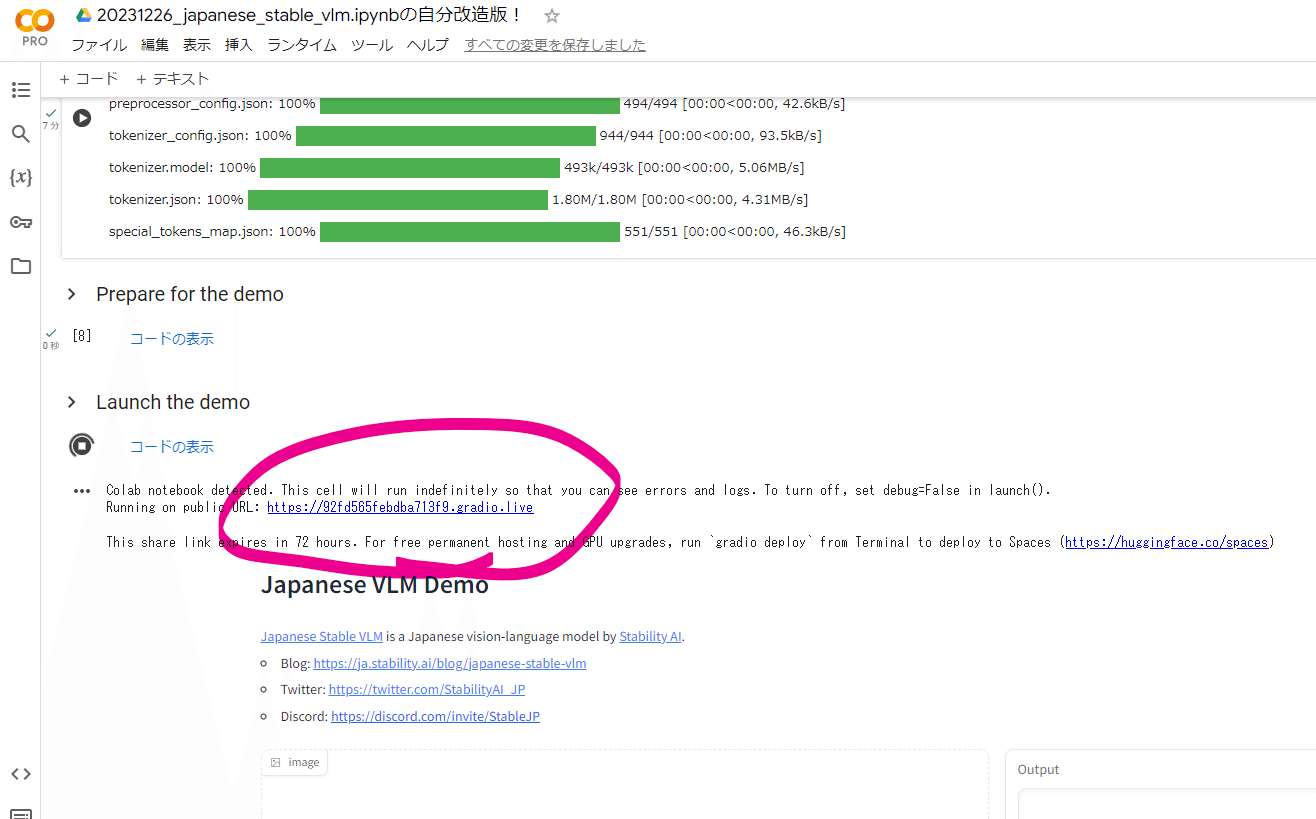
なお、この Gradio の WebUIのURLは世界中からアクセスできます。スマホでもアクセスできます。ご自身のPCではなく Google Colab へのトンネルなので、何も危ないことはないです。URLは72時間有効です。
(12) 明示的に終了させたい時は…
ブラウザを閉じれば時間で終わりますが、こちらの 停止[□] ボタンを押してブラウザのタブを閉じましょう。よく見ると最後のセルの出力には日本語VLMへの「指示、入力、応答」が記載されています。内部の命令も日本語で書かれているということがわかります。これは SpeechToText を使って日本語の声で入力することも便利かもしれませんね。
Keywords
References
※本記事は Stability AI社の協力に基づきAICU社が製作しております。
AICU(アイキュー)は「つくる人をつくる・わかるAIを届ける」をビジョンとしている、デジタルハリウッド大学発の米国スタートアップ企業です。生成AIに関する国際的なニュース・調査・社会理解のための情報発信、生成AIのクリエイティブな使い方TIPS、優しい用語集や書籍開発、エンターテイメント分野や、Stability AI社などの生成AIにおける世界トップ企業とのコラボレーションによる、プロフェッショナルビジネスへの応用ツール開発、社内展開ワークショップ、AI活用ハッカソンなどを展開しております。共同研究・受託開発・インターンなどお問い合わせやご相談はお気軽に X@AICUai までどうぞ。

Comments