
AICUメディア事業部のKotoneです!
前回の記事にて、10月30日(月)から11月2日(木)にシリコンバレーで行われた「ODSC West(Open Data Science Conference)」というデータサイエンスのカンファレンスをレポートしました。
(前回)シリコンバレーからみた生成AI - Stable Diffusionの重要性
この記事では、生成AIの誕生からStableDiffusionの発表、画像生成AIの急速な発展を再確認しました。
今回は第2弾ということで、シリコンバレー在住のKojiのレポートから、前回の続きをお伝えします。
Diffusion Model(拡散モデル)を使った世界初のオープンソースの技術であるStable Diffisionは、一体どういった経緯で生まれたのでしょうか。
Stable Diffusionは、ドイツのミュンヘン大学のコンピュータビジョン研究所の Bjorn Ommer(ビヨン・オマール)教授が開発した Latent Diffusion Model(LDM) という技術をベースとして、RunwayML社の Patrick Esser氏と StablityAI社 の Robin Rambach氏が協力して開発されたものです。

Stable DiffusionはイギリスのStabilityAI社によって発表され、3つの重要な特徴を有しています。
①オープンソースコード
②学習とファインチューニングが容易
③一般ユーザレベルのGPUで稼働する
開発費はわずか60万ドルでしたが、2022年10月には101Mドルを資金調達できたそうです。StablityAI社は元々ヘッジファンドマネージャーであったEmad氏によって2019年に設立された企業です。

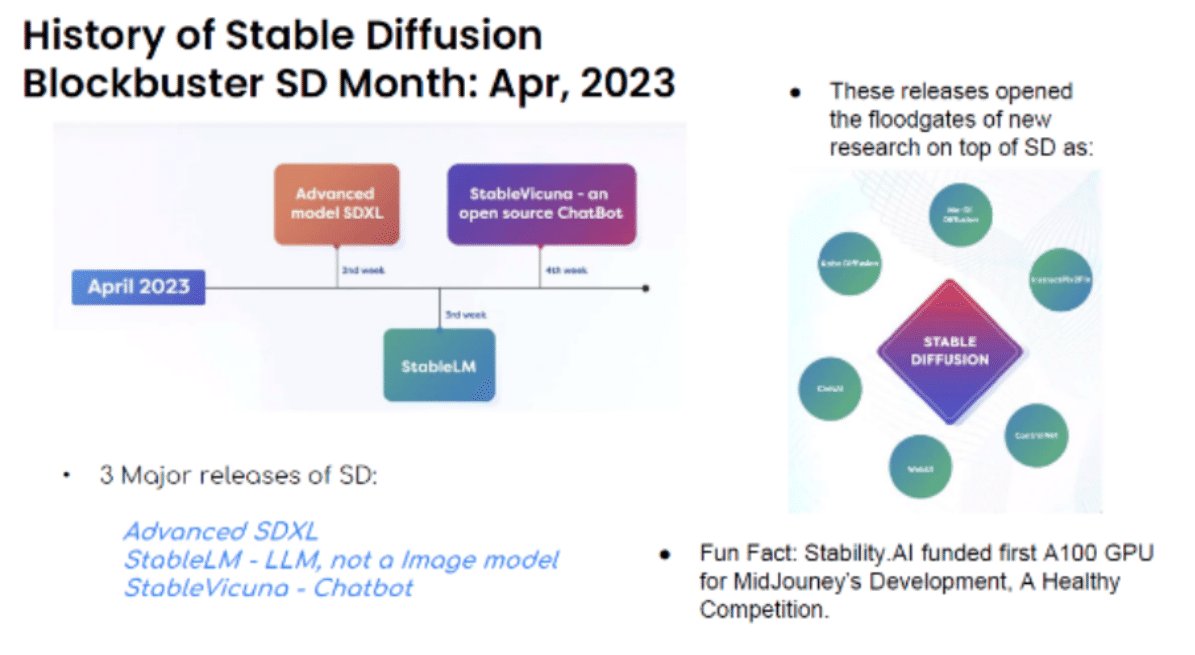
2023年4月はStable Diffusionにとって大躍進の月でした。Advanced SDXL、Stable LM (LLM)、Stable Vicuna(Chatbot)の3つの新しいツールが発表されました。。これらにより、Mo-Di Diffusion、InstructPix2Pix、ControlNet、WebUI、CivitAI、Robo Diffusionなど他社の様々な関連技術の開発が誘発されました。
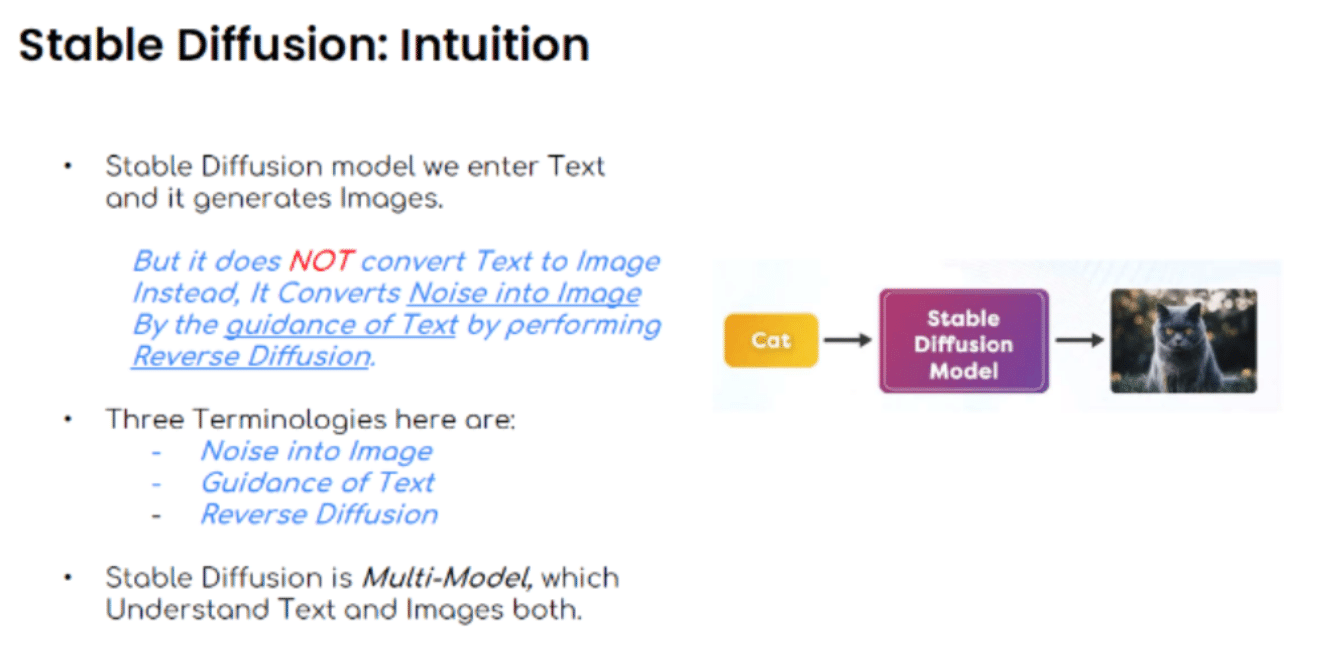
以下はStable Diffusionの直感的な解説です。テキストからイメージを作ります。たとえば、「ネコ」から「ネコの写真」を生成します。しかし、テキストを直接変換するものではありません。テキストの指示にしたがって、リバースディフュージョン(逆拡散)によって、ノイズからイメージを生成するのです。これは3つの技術要素でできています。
①Noise to Image:ノイズから画像を生成する
②Guidance of Text:テキストによるガイダンス
③Reverse Diffusion:逆拡散
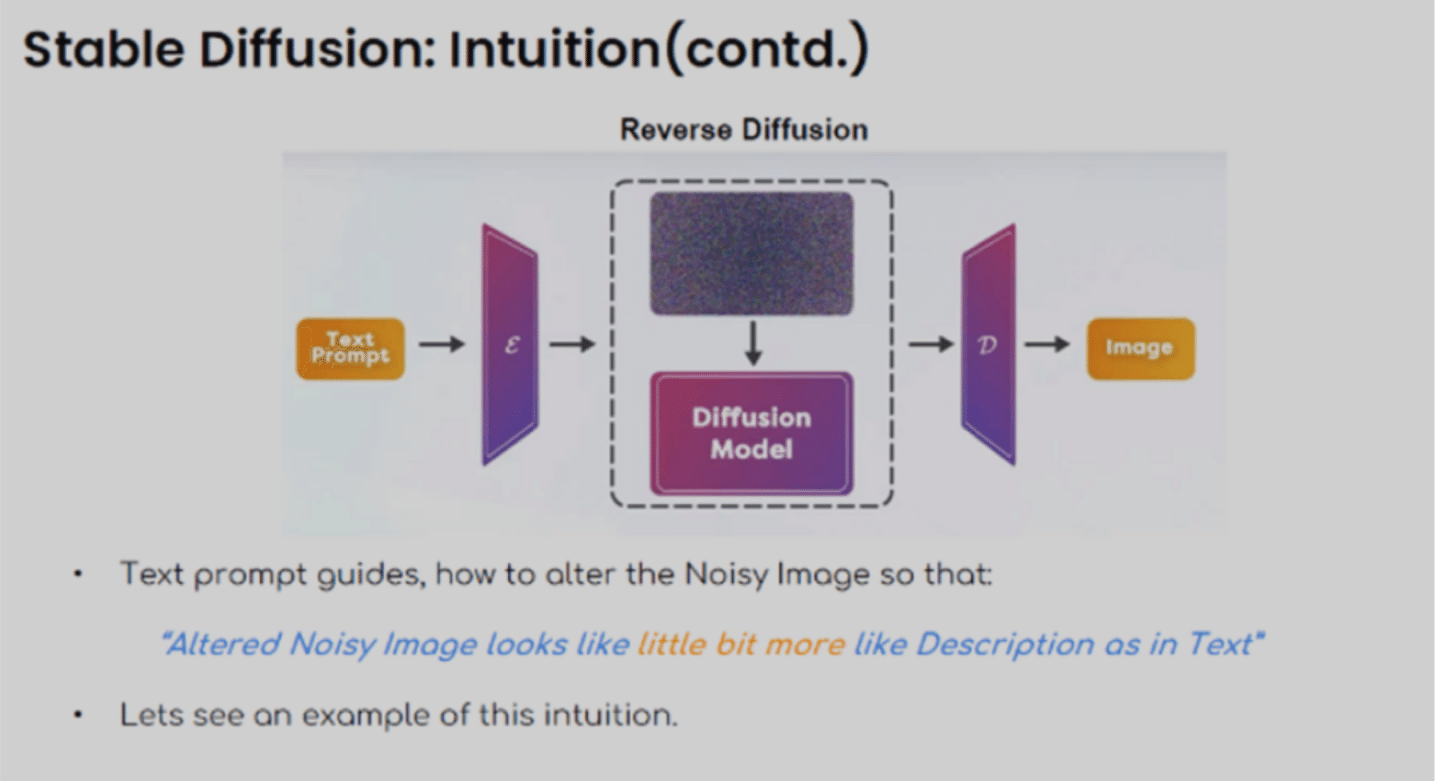
テキストプロンプトは、「変更されたノイズのある画像は、テキストの説明文に少し似ている」といったように、ノイズ画像を変更する方法を指示(ガイダンス)します。
この直感の例を見てみましょう。この例では、入力テキスト "Boy"(少年)に対して、この画像 が与えられたとします。さて、この少年の画像のどこに問題があるでしょうか? 耳と頭を変える必要がありますね。そこで、"Boy "というテキストが "ears "(耳)を変更するようガイド(指示)します。Stable Diffusionでは、このガイドはピクセルレベル、つまり1ドット単位で行います。エンコードされたテキストは、どのピクセルを少しだけ変更するか教えます。

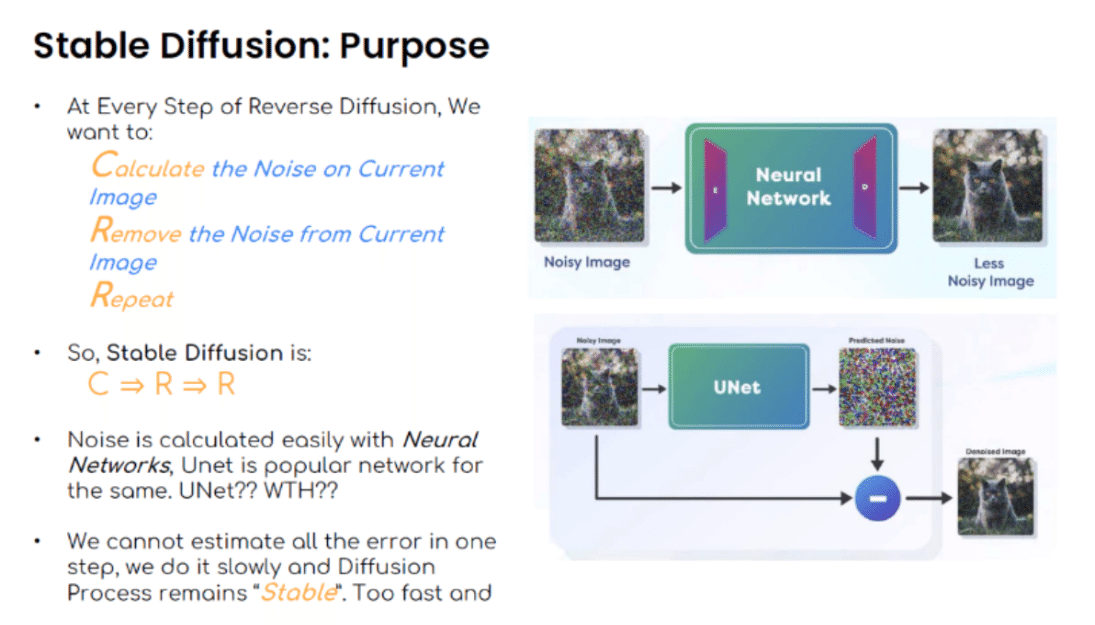
Stable Diffusionの直感的な画像生成プロセスです。Forward Diffusion(順方向拡散)はノイズを加えることで、Reverse Diffusion(逆拡散)は「ノイズ除去処理」です。

Calculate:現在の画像のノイズ加算
Remove:現在の画像のノイズを取り除く(Denoising)
Repeate:繰り返し
Stable Diffusion は、このノイズ付加⇒ノイズ除去⇒繰り返し…の繰り返しです。実はノイズの生成や逆のノイズ除去計算はニューラルネットワークで容易に行うことができます。しかし、すべてのエラーを一度のステップで予測することは出来ませんので、ステップバイステップで行っていきます。
特に画像からノイズを除去するプロセスには膨大な時間がかかります。その時間を短縮するため Stable DiffusionではLatent Space(潜在空間)という概念を利用します。複雑で膨大な画像データを「その画像の特徴を表す、より少ない次元」で表現する「特徴ベクトル」として扱うことで、画像生成に利用するパラメーター数を削減します。
たとえば、人の顔を表現するのに、画像の一つ一つのピクセルの情報で表現しようとするとデータ量は大きくなりますが、髪の色、目の色、顔の形、などの特徴を数値(ベクトル)で表すことにすると、大幅にデータ圧縮することができます。

Stable DiffusionはLatent Stable Diffusionを示します。そして以下の3つの要素で理解できます。
Latent(潜在):エンコードされた入力、デコードされた出力
Stable(安定):ノイズを除去するための小さな変更
Diffusion(拡散):ノイズ除去

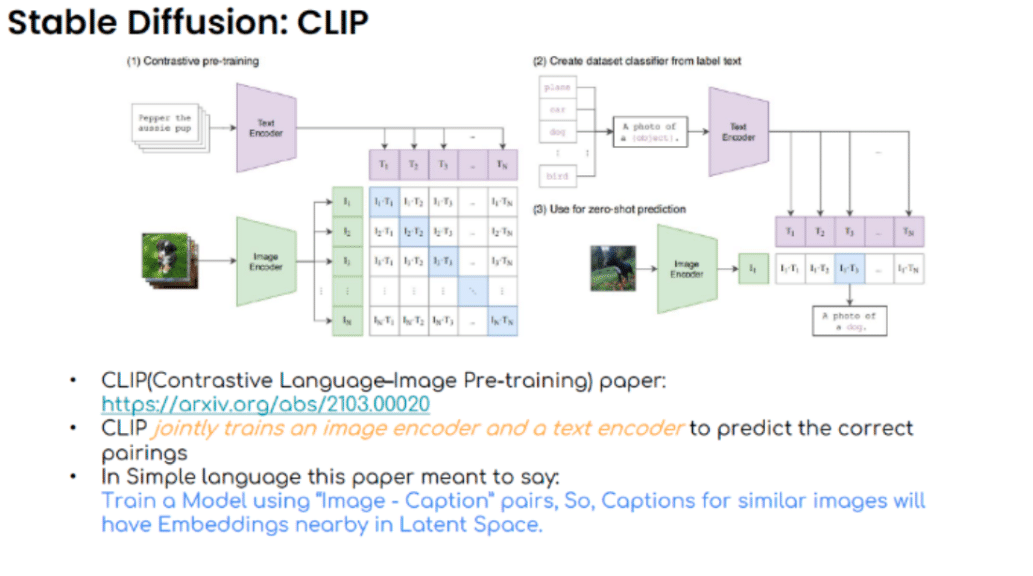
テキストからノイズを計算するためのガイダンス(指示)をどのように受け取るのでしょうか?テキストもまたLatent Space(潜在空間)にエンコードされます。しかし、それはテキスト自体の潜在空間です。画像とテキストが潜在空間で交わるこのプロセスは、すべてのテキストから画像へのモデルの基礎です。この現象により、テキストと画像モデルの境界線が曖昧になっています。そしてこのことは、次の論文で解決されました。2021年のCLIP論文です。

CLIP(Contrastive Language–Image Pre-training、対照的な言語–画像事前トレーニング)とは、テキストと画像のデータペアを同時に理解することを目的とした技術です。具体的には、テキストの説明と対応する画像を関連付けることで、モデルは特定のテキスト記述にマッチする画像を生成する能力を学びます。
CLIPは以下のように機能します。
1.事前学習: CLIPモデルは、インターネットから収集された大量のテキストと画像のペアで事前学習されます。この学習プロセスでは、テキストエンコーダと画像エンコーダが使用され、それぞれがテキストと画像のデータを高次元の潜在空間にマッピングします。
2.コントラスト学習: この潜在空間内で、正しいテキストと画像のペアは近接して表現され、誤ったペアは離れた位置に表現されるように学習されます。これにより、モデルは正確なマッチングを予測できるようになります。
3.ゼロショット学習: CLIPはゼロショット学習能力も持っています。訓練中に見たことがない新しいカテゴリの画像やテキストに対しても、正確な関連付けを行うことができます。
CLIP(Contrastive Language–Image Pre-training) の論文: https://arxiv.org/abs/2103.00020
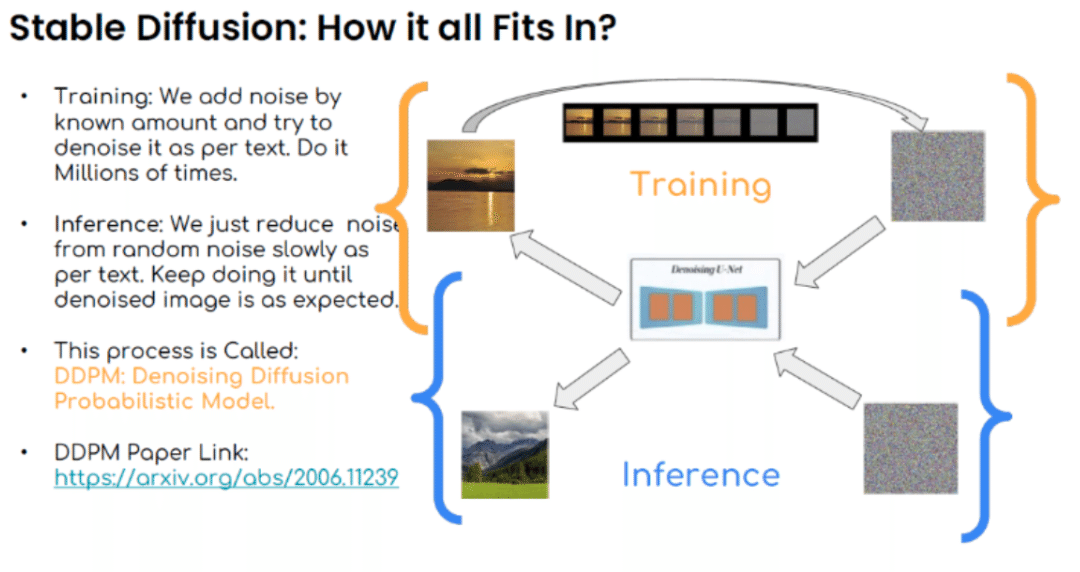
Stable Diffusionは、DDPM(Denoising Diffusion Probabilistic Model)と呼ばれるプロセスを活用しています。このプロセスは、大量のデータセットで何百万回も行われるトレーニングと、実際に画像を生成する際の推論の2つの主要なステップに分けられます。
1.トレーニング:トレーニング段階では、既知の量のノイズを画像に加え、テキスト情報に基づいてそのノイズを除去する方法をモデルが学習します。このプロセスは何百万回も繰り返され、モデルはテキストと画像の対応関係をより正確に理解するようになります。
2.推論: 推論段階では、ランダムなノイズからスタートし、テキスト情報に従って徐々にノイズを減らしていきます。このプロセスを繰り返し行い、テキスト情報に合致した、ノイズのない画像が得られるまで続けます。
DDPMは、ノイズのあるデータからノイズを除去していくことでデータの本来の分布を学習する確率的モデルであり、このアプローチによってテキストから画像を生成することが可能になります。
DDPMの論文: https://arxiv.org/abs/2006.11239

Kotoneの感想
画像生成に使われている専門用語を分解して理解することで、どのような技術が使われているのかを理解できました。画像生成とLLMは一見関係ないように感じますが、TransformerやCLIPをはじめとしてテキストと画像を結びつける技術にLLMが関わっているのだと実感できました。
次回はOSDC編の最終回、もう一歩踏み込んでVAEなどの解説に入っていきます!
Comments