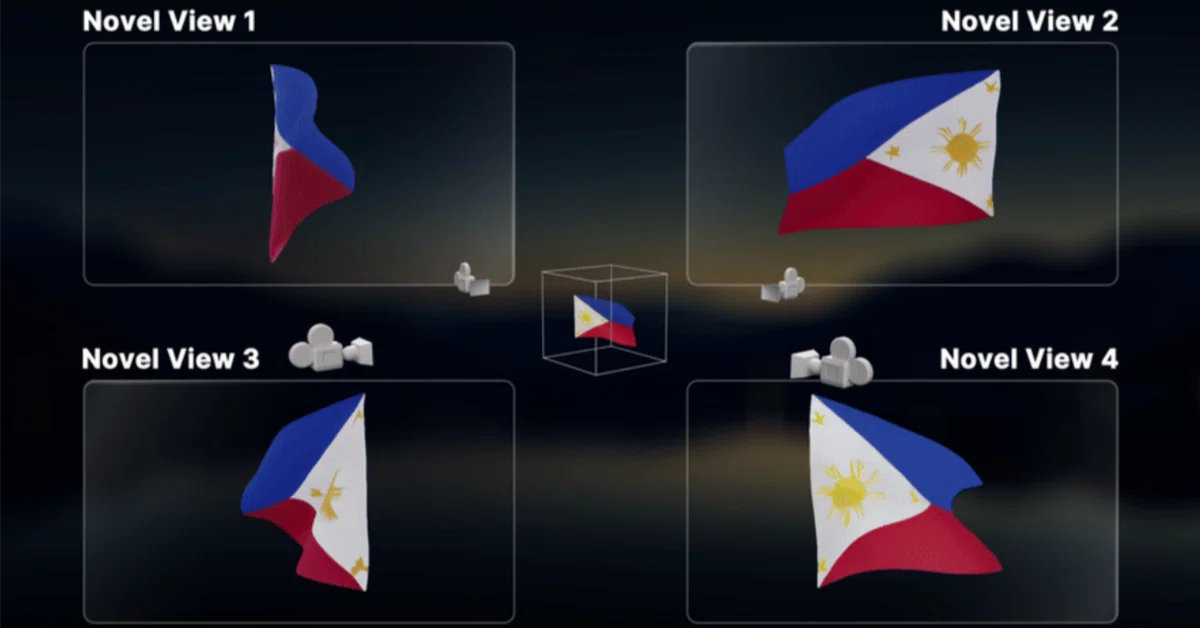
2024年7月24日、Stability AI は同社の初の Video to Video生成モデルである動的多視点動画生成技術「Stable Video 4D」を提供開始しました。1本のビデオから8つの新しいアングルの動的で斬新な視点の動画を生成できます。
この発表に合わせて、このモデル開発で達成された方法論、課題、ブレークスルーを詳述した包括的な技術レポートも公開されています。
Stable Video 4D (英語ページ)
日本語公式リリース
https://ja.stability.ai/blog/stable-video-4d
主なポイント:
- Stable Video 4D は、1つの目的の動画から、8 つの異なる角度/視点からの斬新な複数視点動画に変換します。
- Stable Video 4D は、1回の推論で、8視点にわたる 5フレームを約40秒で生成します。
- ユーザーはカメラアングルを指定して、特定のクリエイティブニーズに合わせて出力を調整できます。
- 現在研究段階にあるこのモデルは、ゲーム開発、動画編集、バーチャルリアリティにおける将来的な応用が期待されており、継続的な改善が進められています。Hugging Face で現在公開中です。
仕組み
ユーザーはまず、単一の動画をアップロードし、目的の3D カメラの姿勢を指定します。次に、Stable Video 4D は、指定されたカメラの視点に従って 8 つの斬新な視点動画を生成し、被写体の包括的で多角的な視点を提供します。生成された動画は、動画内の被写体の動的な 3D 表現を効率的に最適化するために使用できます。
現在、Stable Video 4D は 8 つの視点にわたって 5 フレームの動画を約 40 秒で生成でき、4D最適化全体には約 20 ~ 25 分かかります。開発チームは、ゲーム開発、動画編集、バーチャルリアリティにおける将来的な応用を構想しており。これらの分野の専門家は、オブジェクトを複数の視点から視覚化する機能から大きな恩恵を受け、製品のリアリズムと没入感を高めることがが可能になります。


最先端のパフォーマンス
画像拡散モデル、動画拡散モデル、多視点拡散モデルの組み合わせからサンプリングする必要がある従来のアプローチとは異なり、SV4D は複数の斬新な視点動画を同時に生成できるため、空間軸と時間軸の一貫性が大幅に向上しています。この機能により、複数の視点とタイムスタンプにわたって一貫したオブジェクトの外観が保証されるだけでなく、複数の拡散モデルを使用した煩雑なスコア蒸留サンプリング (Score Distillation Sampling: SDS) を必要としない、より軽量な 4D 最適化フレームワークが可能になります。
Stable Video 4D は、既存の事例と比較して、より詳細で、入力動画に忠実で、フレームと視点間で一貫性のある斬新な視点動画を生成できます。
研究開発
Stable Video 4D は Hugging Face で公開されており、Stability AI 初の動画から動画への生成モデルであり、エキサイティングなマイルストーンとなっています。現在トレーニングに使用されている合成データセットを超えて、より幅広い実際の動画を処理できるように、モデルの改良と最適化に積極的に取り組んでいます。
テクニカルレポート
この発表と併せて、このモデルの開発中に達成された方法論、課題、ブレークスルーを詳述した包括的な技術レポートが公開されています。
https://sv4d.github.io/static/sv4d_technical_report.pdf
リポジトリより(VRAM40GB以上必要)
Hugging Face でのモデル配布は実施されていますが、そのまま試すことは難しい状態です。AICU AIDX LabではローカルおよびGoogle Colab Pro環境で実験してみました(結論はVRAMが40GB以上必要で、動作確認には至っていません)。ノートブックへのリンクは文末にて。
Stability AI の GitHub では Generative Models というリポジトリでサンプルコードが提供されています。
SV4D helper
https://github.com/Stability-AI/generative-models/blob/main/scripts/demo/sv4d_helpers.py
Sample code
https://github.com/Stability-AI/generative-models/blob/main/scripts/sampling/simple_video_sample_4d.py
事前準備
まず Hugging Face で以下のモデルについてライセンス登録を行う必要があります。
https://huggingface.co/stabilityai/sv4d
https://huggingface.co/stabilityai/sv3d
次にGPUメモリが40GB以上搭載された環境をご準備ください。
Google Colab Pro+ でA100環境をご準備ください。
Hugging Face Access Token キー を HF_TOKEN という名前で Google Colab左側の「シークレット」に設定します。

sv4d.safetensors と sv3d_u.safetensors を ./checkpoints/ にダウンロードします。
SV4Dは、5つのコンテキストフレーム(入力映像)と、同じサイズの8つの参照ビュー(SV3Dのようなマルチビュー拡散モデルを使用して、入力映像の最初のフレームから合成された)が与えられ、576×576の解像度で40フレーム(5ビデオフレームx8カメラビュー)を生成するように訓練されています。より長い新規のビュー動画(21フレーム)を生成するために、まず5つのアンカーフレームをサンプリングし、次に時間的な一貫性を保ちながら残りのフレームを高密度にサンプリングするという、SV4Dを用いた新しいサンプリング方法を提案します。
例えば21フレームの単一の入力動画でSV4Dを実行するには:
generative-models ディレクトリから
以下のコマンドを実行します。
python scripts/sampling/simple_video_sample_4d.py –input_path <path/to/video>
起動時パラメータとしては以下のとおりです。
- input_path: 入力動画
は、 - assets/test_video1.mp4のような gif または mp4 形式の単一のビデオファイル
- .jpg、.jpeg、または.png形式の(連番)ビデオフレームの画像を含むフォルダ
- ビデオフレームの画像に一致するファイル名パターン
を指定できます。
- num_steps: デフォルトは20です。より高い品質を得るには50に増やすことができますが、サンプリング時間が長くなります。
- sv3d_version: 参照マルチビューを生成するために使用するSV3Dモデルを指定するには、SV3D_uの場合は –sv3d_version=sv3d_u、SV3D_pの場合は –sv3d_version=sv3d_p を設定します。
- elevations_deg: SV3D_p(デフォルトはSV3D_u)を使用して、指定された仰角(デフォルトの仰角は10)でノベルビュー動画を生成するには、 python scripts/sampling/simple_video_sample_4d.py –input_path test_video1.mp4 –sv3d_version sv3d_p –elevations_deg 30.0 を実行します。
- 背景削除: 無地の背景を持つ入力動画の場合、(オプションで) –remove_bg=True を設定することで、rembgを使用して背景を削除し、ビデオフレームをトリミングします。ノイズの多い背景を持つ現実世界の入力動画でより高品質の出力を得るには、SV4Dを実行する前に、Cliipdropを使用して前景オブジェクトをセグメント化してみてください。
# このままだと A100 GPU (40GB)でも動作しない
#!python scripts/sampling/simple_video_sample_4d.py –input_path assets/test_video1.mp4 –output_folder outputs/sv4d
import os
os.environ[‘PYTORCH_CUDA_ALLOC_CONF’] = ‘max_split_size_mb:512’
#パラメータを小さくしてみましたが動かず
!python scripts/sampling/simple_video_sample_4d.py \
–input_path assets/test_video2.mp4 \
–output_folder outputs/sv4d \
–model_path checkpoints/sv4d.safetensors \
–model_path_sv3d checkpoints/sv3d_u.safetensors \
–batch_size 1 \
–height 32 –width 32 \
–num_steps 1
# どなたか動作確認していただける方を募集します!
Stable_Video_4D.ipynb https://j.aicu.ai/SVD4D

Originally published at https://note.com on July 24, 2024.
Comments