On 2024/07/10, Japan time, a research group led by Lvmin Zhang, a Ph.D. student at Stanford University and the developer of ‘Fooocus,’ ‘Omost,’ and ‘Style2Paint’ (GitHub account: lllyasviel), shared exciting new research findings. They also released experimental code that can be tested on Google Colab.
https://note.com/aicu/n/n8990c841e373
Outstanding Demo
Please be sure to check out the results on this demo site.
https://lllyasviel.github.io/pages/paints_undo
Please note that all input images on this webpage were generated by AI. There is no 'ground truth' or 'correct drawing process' for these images. The process you see is generated based on a single image created by AI, simulating the steps it might have taken to create it, much like a timelapse video of an illustrator's work.

Experiments beyond the realm of bishoujo illustrations.


Generating Rough Sketches

Reproducing Different Drawing Processes



Examples of Failures



Below, I will provide a translation of the official README, supplemented with additional explanations.
https://github.com/lllyasviel/Paints-UNDO
An example of it in action will be introduced at the end.

Paints-Undo: A Base Model for Drawing Actions in Digital Painting
Paints-Undo is a project aimed at providing a base model of human drawing actions to ensure that future AI models can better align with the true needs of human artists.
The name 'Paints-Undo' comes from the fact that the model's output resembles what you would see if you repeatedly pressed the 'Undo' button (usually Ctrl+Z) in digital painting software.
Paints-Undo is a group of models that takes an image as input and outputs the drawing sequence of that image. These models can represent various human actions, such as sketching, inking, coloring, shading, transforming, flipping horizontally, adjusting color curves, changing layer visibility, and even altering the overall concept during the drawing process.
How to Use
PaintsUndo can be deployed locally using the following method. You'll need to have conda installed and at least 10GB of VRAM.
git clone https://github.com/lllyasviel/Paints-UNDO.git
cd Paints-UNDO
conda create -n paints_undo python=3.10
conda activate paints_undo
pip install xformers
pip install -r requirements.txt
python gradio_app.py Inference has been tested on Nvidia 4090 and 3090TI with 24GB VRAM. It may work with 16GB VRAM, but it will not run on 8GB. Based on my estimation, with extreme optimization (including weight offloading and sliced attention), the theoretical minimum VRAM requirement is around 10 to 12.5GB.
Depending on the settings, processing a single image takes about 5 to 10 minutes. Typically, you will get a 25-second video at 4 FPS with a resolution of 320×512, 512×320, 384×448, or 448×384.
Since the processing time is significantly longer than most tasks/quotas on HuggingFace Space, it is not recommended to deploy this on HuggingFace Space to avoid placing unnecessary strain on their servers.
If you do not have the required computational device but still need an online solution, you can wait for the release of a Colab notebook (though it is uncertain whether it will work within the free tier of Colab).
Notes on the Model
Currently, we have released two models: paints_undo_single_frame and paints_undo_multi_frame. We will refer to them as the single-frame model and the multi-frame model, respectively.
The single-frame model takes an image and an operation step as input and outputs a single image.
It assumes that any piece of artwork can be created with 1,000 human operations (for example, one brush stroke counts as one operation, with operation steps ranging from 0 to 999).
Step 0 represents the completed final artwork, while step 999 represents the very first brush stroke on a blank canvas.
This model can be understood as an 'Undo (Ctrl+Z)' model. By inputting the final image and indicating how many times you'd like to press 'Ctrl+Z,' the model will display the 'simulated' screenshot after those 'Ctrl+Z' operations. For example, if the operation step is 100, it means simulating 100 'Ctrl+Z' presses on this image and obtaining the appearance after the 100th 'Ctrl+Z.'
The multi-frame model takes two images as input and outputs 16 intermediate frames between the two input images. While the results are far more consistent than those of the single-frame model, it is much slower, less 'creative,' and limited to 16 frames.
In this repository, the default method combines these two models. First, the single-frame model is inferred 5 to 7 times to obtain 5 to 7 'keyframes.' Then, the multi-frame model is used to 'interpolate' these keyframes, effectively generating a relatively long video.
In theory, this system can be used in various ways, even to create infinitely long videos. However, in practice, it produces good results when the final number of frames is around 100 to 500.
Model Architecture (paints_undo_single_frame)
This model is a modified architecture of SD1.5, trained with different beta schedulers, clip skip, and the aforementioned operation step conditions. Specifically, this model has been trained using the following beta settings:
betas = torch.linspace(0.00085, 0.020, 1000, dtype=torch.float64)
For comparison, the original SD1.5 was trained using the following beta settings
betas = torch.linspace(0.00085 ** 0.5, 0.012 ** 0.5, 1000, dtype=torch.float64) ** 2
You will notice the difference in the final beta and the removed squared term. The choice of this scheduler is based on internal user research.
The final layer of the text encoder CLIP ViT-L/14 is completely removed. The operation step condition is added to the layer embeddings in a manner similar to the additional embeddings in SDXL.
Additionally, since the sole purpose of this model is to process existing images, it is strictly aligned with the WD14 Tagger without any other modifications. To process the input image and obtain a prompt, you must always use the WD14 Tagger (the one available in this repository). Otherwise, the results may be flawed. Prompts written by humans have not been tested.

Model Architecture (paints_undo_multi_frame)
This model is trained by resuming from the VideoCrafter family, but it does not use the original Crafter's lvdm. All training and inference code has been entirely implemented from scratch. (By the way, the code is based on the latest Diffusers.) While the initial weights are resumed from VideoCrafter, the neural network topology has been significantly altered, and after extensive training, the network's behavior is notably different from the original Crafter.
The overall architecture is similar to Crafter, consisting of five components: 3D-UNet, VAE, CLIP, CLIP-Vision, and Image Projection.
- VAE: The VAE is the same anime VAE extracted from ToonCrafter. Special thanks to ToonCrafter for providing an excellent temporal VAE for anime to the Crafters.
- 3D-UNet: The 3D-UNet has been modified from the Crafter's lvdm, including revisions to the attention modules. Apart from some minor code changes, the main modification is that the UNet is now trained to support temporal windows within spatial self-attention layers. The code for diffusers_vdm.attention.CrossAttention.temporal_window_for_spatial_self_attention and temporal_window_type has been adjusted to enable three types of attention windows.
- 'prv' Mode: The spatial self-attention for each frame also attends to the entire spatial context of the previous frame. The first frame only attends to itself.
- 'First' Mode: The spatial self-attention for each frame also attends to the entire spatial context of the first frame in the sequence. The first frame only attends to itself.
- 'roll' Mode: The spatial self-attention for each frame also attends to the entire spatial context of the preceding and following frames based on the order of torch.roll.
- CLIP: The CLIP from SD2.1.
- CLIP-Vision: An implementation of CLIP Vision (ViT/H) that supports any aspect ratio by interpolating positional embeddings. After testing linear interpolation, nearest neighbor, and rotary position encoding (RoPE), the final choice was nearest neighbor. It's important to note that this differs from the Crafter method, which resizes or center-crops images to 224×224.
- Image Projection: An implementation of a small transformer that takes two frames as input and outputs 16 image embeddings for each frame. It's important to note that this differs from the Crafter method, which uses only a single image.
Disclaimer
This project aims to develop a base model of human drawing actions to enable future AI systems to better meet the true needs of human artists. Users are free to create content using this tool, but they must comply with local laws and use it responsibly. Users should not use the tool to generate false information or incite conflict. The developers bear no responsibility for any misuse of the tool by users.
Testing It in Action
✨️ Considering the social impact, the code that runs on Google Colab will be available exclusively to members at the end of the document for the time being.✨️
Please modify the last line of gradio_app.py as follows:
#block.queue().launch(server_name=’0.0.0.0′)
↓
block.queue().launch(server_name=’0.0.0.0′, share=True)
Tutorial
Once you've entered the Gradio interface:
Step 0: Upload an image or click [Sample Image] at the bottom of the page.

Step 1: In the UI titled 'Step 1,' click [Generate Prompt] to obtain the global prompt.

Step 2: In the UI titled 'Step 2,' click [Generate Keyframes]. You can modify the seed and other parameters on the left side.

Step 3: In the UI titled 'Step 3,' click [Generate Video]. You can modify the seed and other parameters on the left side.
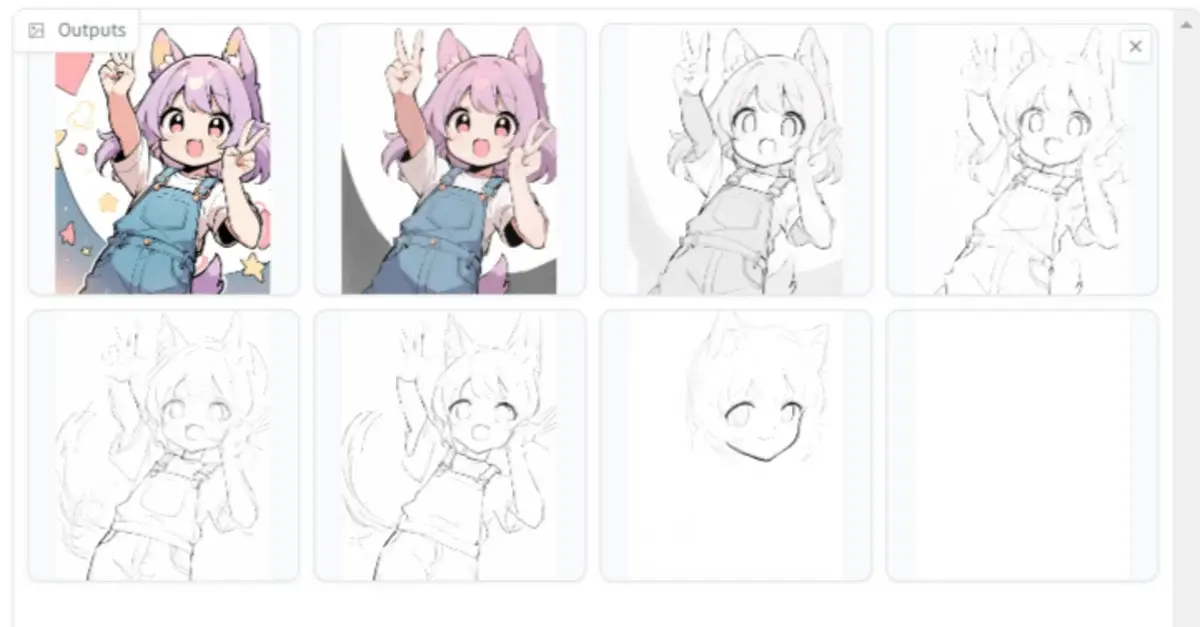
Tried It with an Original Image
We got allowed materials reuse authorization from AICU illustrator Bow Inusawa.






Here's the video
Mr. Inuzawa: 'The way it looks like I'm hesitating at the beginning, it's really quite fitting...'
The technology for inferring drawing processes has the potential to create tools that can be useful in various creative workflows. We are grateful to lllyasviel and the Paints-Undo Team for releasing this as an open technology.
https://github.com/lllyasviel/Paints-UNDO
A notebook for installing conda on Google Colab and using Paints-UNDO
Considering the social impact, we will be offering this exclusively to members for the time being. Please refrain from any misuse. Creating fake videos or using this in a way that disrespects illustrators who draw by hand benefits no one.
Let me reiterate the original disclaimer:
This project aims to develop a base model of human drawing actions to enable future AI systems to better meet the true needs of human artists. Users are free to create content using this tool, but they must comply with local laws and use it responsibly. Users should not use the tool to generate false information or incite conflict. The developers bear no responsibility for any potential misuse of the tool by users.
Continue reading the article here
https://note.com/aicu/n/n7e654dcf405c

Originally published at https://note.com on July 9, 2024.
Comments